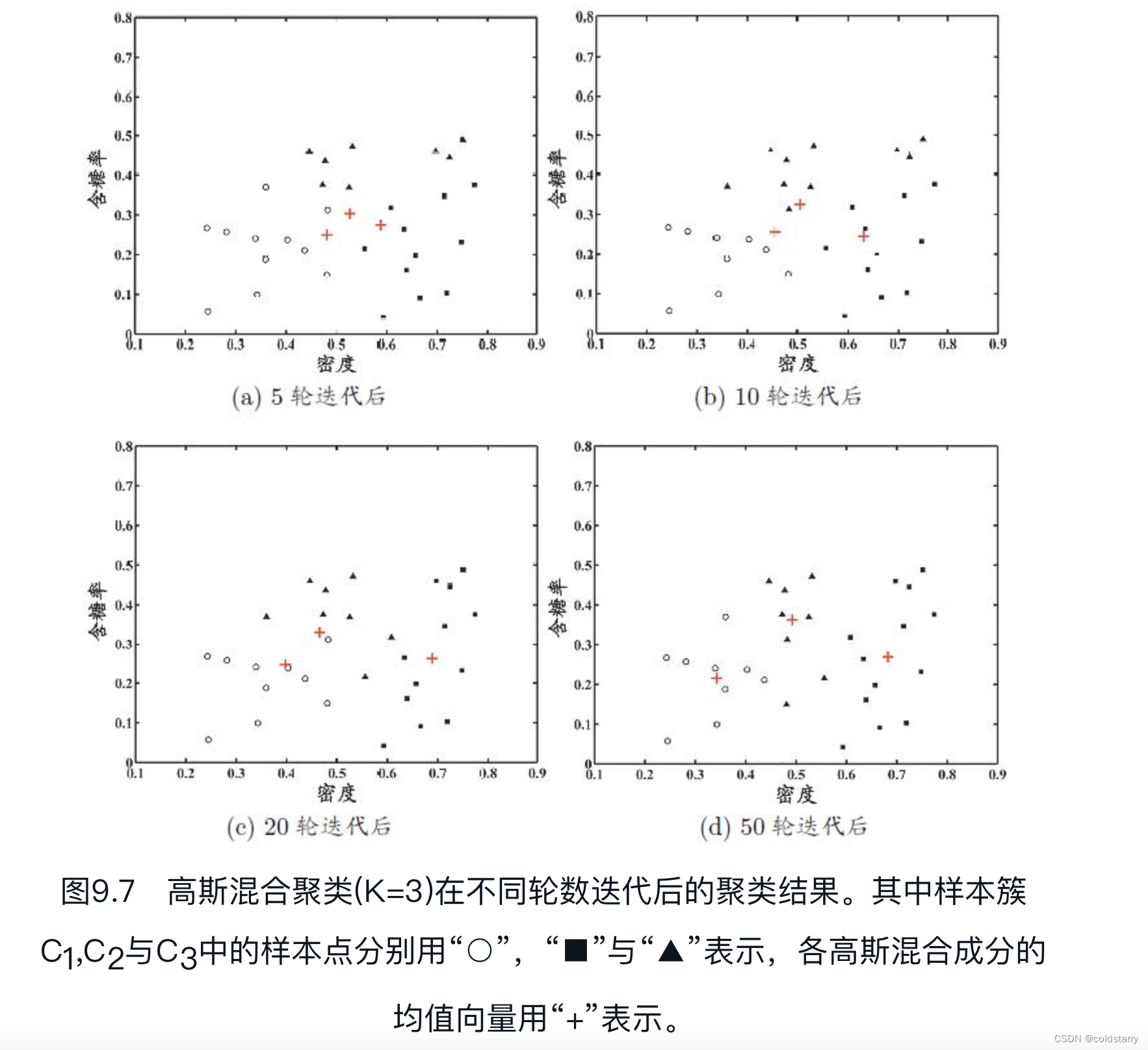
下面是一个简化的 MoE 模型的代码示例,其中包括一个 TopKRouter 和多个专家的实现。在这个例子中,我们使用 PyTorch 框架来定义模型。
import torch
import torch.nn as nn
import torch.nn.functional as F
class Expert(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, inputs):
return self.fc(inputs)
class TopKRouter(nn.Module):
def __init__(self, input_dim, num_experts, top_k):
super().__init__()
self.projection = nn.Linear(input_dim, num_experts)
self.top_k = top_k
def forward(self, inputs):
# 计算每个专家的分数
scores = self.projection(inputs)
# 获取Top-K分数和对应的索引
top_k_scores, top_k_indices = torch.topk(scores, self.top_k, dim=1)
# 将Top-K分数转换为概率分布
probabilities = F.softmax(top_k_scores, dim=1)
return probabilities, top_k_indices
class MixtureOfExperts(nn.Module):
def __init__(self, input_dim, output_dim, num_experts, expert_dim, top_k):
super().__init__()
self.router = TopKRouter(input_dim, num_experts, top_k)
self.experts = nn.ModuleList([
Expert(expert_dim, output_dim) for _ in range(num_experts)
])
self.gate = nn.Softmax(dim=-1)
def forward(self, inputs):
# 根据输入数据获取路由概率和Top-K专家索引
probabilities, expert_indices = self.router(inputs)
# 将输入数据广播到所有专家
inputs = inputs.unsqueeze(1).expand(-1, len(self.experts), -1)
# 根据Top-K索引选择对应的专家
expert_outputs = torch.zeros_like(inputs).scatter(1, expert_indices, inputs)
# 将选择的输入数据传递给对应的专家
expert_results = [expert(expert_outputs[:, i, :]) for i, expert in enumerate(self.experts)]
# 合并所有专家的输出
combined_results = torch.stack(expert_results, dim=1)
# 使用门控网络调整每个专家的输出权重
gate_weights = self.gate(combined_results.mean(dim=0))
# 加权求和得到最终输出
final_output = torch.sum(combined_results * gate_weights.unsqueeze(0), dim=1)
return final_output, probabilities
# 定义模型参数
input_dim = 10 # 输入特征维度
output_dim = 1 # 输出维度
num_experts = 5 # 专家数量
expert_dim = 10 # 每个专家处理的特征维度
top_k = 3 # Top-K路由
# 创建MoE模型实例
model = MixtureOfExperts(input_dim, output_dim, num_experts, expert_dim, top_k)
# 创建一个假设的输入张量
inputs = torch.randn(2, input_dim) # 假设batch大小为2
# 获取模型输出
output, probabilities = model(inputs)
print("Model output:", output)
print("Routing probabilities:", probabilities)
在这个示例中,我们定义了三个主要组件:
Expert:代表单个专家的网络,这里简化为一个线性层。TopKRouter:负责根据输入数据计算分数,并选择Top-K个专家。MixtureOfExperts:MoE模型,包含多个专家和一个路由器。它定义了如何将输入数据分配给专家,如何聚合专家的输出,并使用门控网络调整每个专家的权重。
请注意,这个示例是为了说明 MoE 模型的基本结构和工作原理,实际应用中可能需要更复杂的网络结构和训练策略。